data structures
This commit is contained in:
parent
53ee3577a1
commit
ce4e78cabf
2 changed files with 1045 additions and 0 deletions
611
15.linked-lists-and-arrays.ipynb
Normal file
611
15.linked-lists-and-arrays.ipynb
Normal file
|
|
@ -0,0 +1,611 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4d5e8ae9-592e-48b1-bf17-9923d267349c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Data Structures: Linked Lists vs. Arrays\n",
|
||||
"\n",
|
||||
"This week we're going to look at implementations of core data structures in Python.\n",
|
||||
"\n",
|
||||
"We'll start with two different ways to represent sequential data: **linked lists** & **arrays**.\n",
|
||||
"\n",
|
||||
"Python's `list` could have chosen either of these, and in some languages like Java or C++ users explicitly choose the implementation most suited to their needs.\n",
|
||||
"\n",
|
||||
"## Arrays\n",
|
||||
"\n",
|
||||
"Arrays are blocks of contiguous memory. \n",
|
||||
"\n",
|
||||
"Each block is the same size, so you can find the memory location of a given block\n",
|
||||
"via `start_position + (idx * block_size)`. That will give the address of a given block, allowing **O(1)** access to any element.\n",
|
||||
"\n",
|
||||
"This means looking up the 0th element takes the same amount of time as the 1,000,00th. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "e774f52f-63cc-4dcf-a8ec-e7ed9197f76f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class Array:\n",
|
||||
" \"\"\"\n",
|
||||
" psuedocode class demonstrating array lookup \n",
|
||||
" \"\"\"\n",
|
||||
" def __init__(self, size, block_size=8):\n",
|
||||
" # need a contiguous block of free memory\n",
|
||||
" self.initial_memory_address = request_memory(amount=size*block_size)\n",
|
||||
" # each \"cell\" in the array needs to be the same number of bytes\n",
|
||||
" self.block_size = block_size\n",
|
||||
" # we need to know how many cells we need\n",
|
||||
" self.size = size\n",
|
||||
" \n",
|
||||
" def __getitem__(self, index):\n",
|
||||
" return read_from_memory_address(\n",
|
||||
" self.initial_memory_address + idx * self.block_size\n",
|
||||
" )"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "fcd44a0c-5fca-4fdb-af1b-b09bb3be5bca",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Python's `list` type is internally implemented as an array.\n",
|
||||
"\n",
|
||||
"- What happens when we need to grow the list?\n",
|
||||
"- what does `list.append` do?\n",
|
||||
"- what does `list.insert(0, 0)` (at the beginning) do?\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "3503e142-c26f-4598-8240-a11b9397147b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Linked Lists\n",
|
||||
"\n",
|
||||
"An alternative way to store sequential items is by using a linked list.\n",
|
||||
"\n",
|
||||
"Linked lists store individual elements and a pointer to the next element. This means that looking up the Nth element requires traversing the entire list.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Linked lists can grow without bound, each new node can be allocated on the fly."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "cfb1a2af-b065-43cf-b7b0-3bfb046d9d85",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class Node:\n",
|
||||
" def __init__(self, value, _next=None):\n",
|
||||
" self.value = value\n",
|
||||
" self.next = _next\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class LinkedList:\n",
|
||||
" def __init__(self):\n",
|
||||
" self.root = None\n",
|
||||
"\n",
|
||||
" def add(self, value):\n",
|
||||
" if self.root is None:\n",
|
||||
" # first value: special case\n",
|
||||
" self.root = Node(value)\n",
|
||||
" else:\n",
|
||||
" cur = self.root\n",
|
||||
" # traverse to end of list\n",
|
||||
" while cur.next:\n",
|
||||
" cur = cur.next\n",
|
||||
" # drop a new node at the end of list\n",
|
||||
" cur.next = Node(value)\n",
|
||||
"\n",
|
||||
" def __str__(self):\n",
|
||||
" s = \"\"\n",
|
||||
" cur = self.root\n",
|
||||
" while cur:\n",
|
||||
" s += f\"[{cur.value}] -> \"\n",
|
||||
" cur = cur.next\n",
|
||||
" s += \"END\"\n",
|
||||
" return s"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "2a796778-c06e-4585-b201-07061d25e561",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[1] -> [3] -> [5] -> [7] -> END\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"ll = LinkedList()\n",
|
||||
"ll.add(1)\n",
|
||||
"ll.add(3)\n",
|
||||
"ll.add(5)\n",
|
||||
"ll.add(7)\n",
|
||||
"print(ll)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "99f36edd-93e8-4658-b5cd-41eed7d9b4ce",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Optimizations\n",
|
||||
"\n",
|
||||
"Doubly linked lists, and more complicated internal pointer structures can lead to increased performance at cost of more memory/complexity.\n",
|
||||
"\n",
|
||||
"(Our first memory vs. runtime trade-off)\n",
|
||||
"\n",
|
||||
"`collections.deque` is a doubly linked list implementation in Python.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "0bfd80aa-4a8d-465c-9c29-aa1aba55c18c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Linked List vs. Array\n",
|
||||
"\n",
|
||||
"**Array**\n",
|
||||
" \n",
|
||||
"- Lookup: O(1)\n",
|
||||
"- Append: O(1) unless at capacity, then expensive O(n) copy\n",
|
||||
"- Insertion: O(n)\n",
|
||||
"\n",
|
||||
"Requires over-allocation of memory to gain efficiency.\n",
|
||||
"\n",
|
||||
"**Linked List** \n",
|
||||
" \n",
|
||||
"- Lookup: O(n)\n",
|
||||
"- Append: O(1)\n",
|
||||
"- Insertion: O(n)\n",
|
||||
"\n",
|
||||
"Requires pointer/node structure to gain efficiency."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9465bc5b-8d44-43bf-83c6-5ede55f722f5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Stack\n",
|
||||
"\n",
|
||||
"A stack is a last-in-first-out (LIFO) data structure that needs to primarily serve two operations: push, and pop.\n",
|
||||
"\n",
|
||||
"Both should be O(1).\n",
|
||||
"\n",
|
||||
"### Usage\n",
|
||||
"\n",
|
||||
"- Undo/Redo\n",
|
||||
"- Analogy: stack of plates -- add to/take from the top\n",
|
||||
"- Call Stacks\n",
|
||||
"\n",
|
||||
"Sometimes when we're writing code we talk about \"the stack\", which is the call stack of functions we're in & their scopes.\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"\n",
|
||||
"def f():\n",
|
||||
" ...\n",
|
||||
" \n",
|
||||
" \n",
|
||||
"def g():\n",
|
||||
" if ...:\n",
|
||||
" f()\n",
|
||||
" else:\n",
|
||||
" ...\n",
|
||||
"\n",
|
||||
"def h():\n",
|
||||
" y = g()\n",
|
||||
" ...\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"When we call h(), it is added to the call stack, then g is added, and f is added on top. We return from these functions in LIFO order, f() exits, then g(), then h().\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "6c73e9f9-17e4-4057-b5fb-d169d0db9b96",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class Stack:\n",
|
||||
" def __init__(self):\n",
|
||||
" self._data = []\n",
|
||||
"\n",
|
||||
" def push(self, item):\n",
|
||||
" # remember: adding/removing at the end of the list is faster than the front\n",
|
||||
" self._data.append(item)\n",
|
||||
"\n",
|
||||
" def pop(self):\n",
|
||||
" return self._data.pop()\n",
|
||||
"\n",
|
||||
" def __len__(self):\n",
|
||||
" return len(self._data)\n",
|
||||
"\n",
|
||||
" def __str__(self):\n",
|
||||
" return \" TOP -> \" + \"\\n \".join(\n",
|
||||
" f\"[ {item} ]\" for item in reversed(self._data)\n",
|
||||
" )\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "1db244c8-9168-4c19-a73c-53a20c48485a",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"called h()\n",
|
||||
" TOP -> [ h() ]\n",
|
||||
"\n",
|
||||
"h called g()\n",
|
||||
" TOP -> [ g() ]\n",
|
||||
" [ h() ]\n",
|
||||
"\n",
|
||||
"g called f()\n",
|
||||
" TOP -> [ f() ]\n",
|
||||
" [ g() ]\n",
|
||||
" [ h() ]\n",
|
||||
"\n",
|
||||
"exited f()\n",
|
||||
" TOP -> [ g() ]\n",
|
||||
" [ h() ]\n",
|
||||
"\n",
|
||||
"exited g()\n",
|
||||
" TOP -> [ h() ]\n",
|
||||
"\n",
|
||||
"exited h()\n",
|
||||
" TOP -> \n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"s = Stack()\n",
|
||||
"s.push(\"h()\")\n",
|
||||
"print('\\ncalled h()')\n",
|
||||
"print(s)\n",
|
||||
"print('\\nh called g()')\n",
|
||||
"s.push(\"g()\")\n",
|
||||
"print(s)\n",
|
||||
"print('\\ng called f()')\n",
|
||||
"s.push(\"f()\")\n",
|
||||
"print(s)\n",
|
||||
"print(\"\\nexited\", s.pop())\n",
|
||||
"print(s)\n",
|
||||
"print(\"\\nexited\", s.pop())\n",
|
||||
"print(s)\n",
|
||||
"print(\"\\nexited\", s.pop())\n",
|
||||
"print(s)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "05fefd4e-4701-437b-b7e8-e5566e753708",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Queue\n",
|
||||
"\n",
|
||||
"A queue is a first-in-first-out (FIFO) data structure that adds items to one end, and removes them from the other.\n",
|
||||
"\n",
|
||||
"We see queues all over the place in everyday life and computing. Most resources are accessed on a FIFO basis."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"id": "4525594e-070b-4bcb-b4c7-a3641f514b2d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class ArrayQueue:\n",
|
||||
" def __init__(self, _iterable=None):\n",
|
||||
" if _iterable:\n",
|
||||
" self._data = list(_iterable)\n",
|
||||
" else:\n",
|
||||
" self._data = []\n",
|
||||
"\n",
|
||||
" def push(self, item):\n",
|
||||
" # adding to the end of the list is faster than the front\n",
|
||||
" self._data.append(item)\n",
|
||||
"\n",
|
||||
" def pop(self):\n",
|
||||
" # only change from `Stack` is we remove from the other end\n",
|
||||
" # this can be slower, why?\n",
|
||||
" return self._data.pop(0)\n",
|
||||
"\n",
|
||||
" def __len__(self):\n",
|
||||
" return len(self._data)\n",
|
||||
"\n",
|
||||
" def __repr__(self):\n",
|
||||
" return \" TOP -> \" + \"\\n \".join(\n",
|
||||
" f\"[ {item} ]\" for item in reversed(self._data)\n",
|
||||
" )\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "20c843b5-9c64-45cb-af77-514b680cbd9c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from collections import deque\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class DequeQueue:\n",
|
||||
" def __init__(self, _iterable=None):\n",
|
||||
" if _iterable:\n",
|
||||
" self._data = deque(_iterable)\n",
|
||||
" else:\n",
|
||||
" self._data = deque()\n",
|
||||
"\n",
|
||||
" def push(self, item):\n",
|
||||
" self._data.append(item)\n",
|
||||
"\n",
|
||||
" def pop(self):\n",
|
||||
" return self._data.popleft()\n",
|
||||
"\n",
|
||||
" def __len__(self):\n",
|
||||
" return len(self._data)\n",
|
||||
"\n",
|
||||
" def __repr__(self):\n",
|
||||
" return \" TOP -> \" + \"\\n \".join(\n",
|
||||
" f\"[ {item} ]\" for item in reversed(self._data)\n",
|
||||
" )\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "3af2e4e7-e600-4201-859b-9b36751a5247",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Performance Testing\n",
|
||||
"\n",
|
||||
"We can try to measure performance something takes by measuring how much time has passed.\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"import time\n",
|
||||
"\n",
|
||||
"before = time.time()\n",
|
||||
"# do something\n",
|
||||
"after = time.time()\n",
|
||||
"elapsed = before - after\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Issue is that in practice, times involved are miniscule, and other events on the system will overshadow differences."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"id": "a414509d-84bb-4ae7-a105-2c6b9dcb7406",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import time\n",
|
||||
"\n",
|
||||
"def print_elapsed(func):\n",
|
||||
" def newfunc(*args, **kwargs):\n",
|
||||
" before = time.time()\n",
|
||||
" retval = func(*args, **kwargs)\n",
|
||||
" elapsed = time.time() - before\n",
|
||||
" print(f\"Took {elapsed} sec to run {func.__name__}\")\n",
|
||||
"\n",
|
||||
" return newfunc\n",
|
||||
"\n",
|
||||
"@print_elapsed\n",
|
||||
"def testfunc(QueueCls):\n",
|
||||
" queue = QueueCls()\n",
|
||||
" for item in range(100):\n",
|
||||
" queue.push(item)\n",
|
||||
" while queue:\n",
|
||||
" queue.pop()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"id": "f1842168-b12d-4d1c-a004-10614904f3f2",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Took 7.605552673339844e-05 sec to run testfunc\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"testfunc(ArrayQueue)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"id": "19a3b107-da59-40f3-bafb-70160747fb53",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Took 7.700920104980469e-05 sec to run testfunc\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"testfunc(DequeQueue)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "0cd093da-0a2c-4adb-96b8-bd56a874f6f2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The differences are just too small to be sure. We need to run our code many more times.\n",
|
||||
"\n",
|
||||
"Python has a built in module for this, `timeit`.\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"import timeit\n",
|
||||
"\n",
|
||||
"timeit.timeit(stmt='pass', setup='pass', timer=<default timer>, number=1000000, globals=None)\n",
|
||||
"\n",
|
||||
"# for more: https://docs.python.org/3/library/timeit.html\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"id": "93010cc5-55c9-4308-b0d0-8fac623f2c55",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"1000000x ArrayQueue.push, took 0.10346049995860085\n",
|
||||
"1000000x DequeQueue.push, took 0.06602491601370275\n",
|
||||
"DequeQueue is 36.183% faster\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import timeit\n",
|
||||
"\n",
|
||||
"number = 1_000_000\n",
|
||||
"\n",
|
||||
"elapsed = timeit.timeit(\n",
|
||||
" \"queue.push(1)\",\n",
|
||||
" setup=\"queue = QueueCls()\",\n",
|
||||
" globals={\"QueueCls\": ArrayQueue},\n",
|
||||
" number=number,\n",
|
||||
")\n",
|
||||
"elapsed2 = timeit.timeit(\n",
|
||||
" \"queue.push(1)\",\n",
|
||||
" setup=\"queue = QueueCls()\",\n",
|
||||
" globals={\"QueueCls\": DequeQueue},\n",
|
||||
" number=number,\n",
|
||||
")\n",
|
||||
"print(f\"{number}x ArrayQueue.push, took\", elapsed)\n",
|
||||
"print(f\"{number}x DequeQueue.push, took\", elapsed2)\n",
|
||||
"print(f\"DequeQueue is {(elapsed-elapsed2) / elapsed * 100:.3f}% faster\")\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 26,
|
||||
"id": "f40f7691-599c-49f9-8f08-30aa14c1e90a",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"10000x ArrayQueue.pop, took 1.7424908330431208\n",
|
||||
"10000x DequeQueue.pop, took 0.0005924999713897705\n",
|
||||
"DequeQueue is 99.966% faster\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"number = 10_000\n",
|
||||
"\n",
|
||||
"elapsed = timeit.timeit(\n",
|
||||
" \"queue.pop()\",\n",
|
||||
" setup=\"queue = QueueCls([0] * 1000000)\",\n",
|
||||
" globals={\"QueueCls\": ArrayQueue},\n",
|
||||
" number=number,\n",
|
||||
")\n",
|
||||
"elapsed2 = timeit.timeit(\n",
|
||||
" \"queue.pop()\",\n",
|
||||
" setup=\"queue = QueueCls([0] * 1000000)\",\n",
|
||||
" globals={\"QueueCls\": DequeQueue},\n",
|
||||
" number=number,\n",
|
||||
")\n",
|
||||
"print(f\"{number}x ArrayQueue.pop, took\", elapsed)\n",
|
||||
"print(f\"{number}x DequeQueue.pop, took\", elapsed2)\n",
|
||||
"print(f\"DequeQueue is {(elapsed-elapsed2) / elapsed * 100:.3f}% faster\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b20fc917-73d2-4378-ae0a-a2119883efa3",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Queue Performance\n",
|
||||
"\n",
|
||||
"| Operation | ArrayQueue | DequeQueue |\n",
|
||||
"| --------- | ---------- | ---------- |\n",
|
||||
"| push | O(1) | O(1) |\n",
|
||||
"| pop | O(n) | O(1) |\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c44f9af3-4a0a-4dad-8bf6-4ec3ecc7d3f1",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"\n",
|
||||
"\n",
|
||||
"For a Stack, an array or linked list can both give O(1) performance.\n",
|
||||
"\n",
|
||||
"For a Queue, a (doubly) linked list is necessary.\n",
|
||||
"\n",
|
||||
"But arrays are superior for indexing operations. And *typical* code indexes list far more than it appends/inserts. Depending on your needs Python's `list` implementation may not be the optimal data structure."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d6c3fd9d-12a3-49a2-aba4-257d8a6eb829",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.15"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
434
16.trees-graphs-tries.ipynb
Normal file
434
16.trees-graphs-tries.ipynb
Normal file
|
|
@ -0,0 +1,434 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f37ff61d-dfe1-4b65-a74d-efe317bbfade",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Data Structures: Trees, Graphs, and Tries"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c12455f1-b6e7-4822-8b20-0da02e8e7a11",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We saw that linked lists use nodes linked in a linear fashion.\n",
|
||||
"\n",
|
||||
"Each node had a \"next\" (and possibly a reference to \"prev\").\n",
|
||||
"\n",
|
||||
"We can use this same idea with additional links to create **Trees**.\n",
|
||||
"\n",
|
||||
"We'll start with a classic **binary search tree**.\n",
|
||||
"\n",
|
||||
"Each node has a value, and up to two children, \"left\" and \"right\".\n",
|
||||
"\n",
|
||||
"Data is stored in the tree such that when a new node is added, if it is less than the current value of a node, it should be stored to the left, and if it is greater, it should be stored to the right.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "012f2a24-f0cc-47ef-a572-3c0825f27850",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class Node:\n",
|
||||
" def __init__(self, value, left=None, right=None):\n",
|
||||
" self.value = value\n",
|
||||
" self.left = left\n",
|
||||
" self.right = right\n",
|
||||
"\n",
|
||||
" def __str__(self):\n",
|
||||
" return f\"({self.value}, {self.left}, {self.right})\"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class BST:\n",
|
||||
" def __init__(self, iterable=None):\n",
|
||||
" self.root = None\n",
|
||||
" if iterable:\n",
|
||||
" for item in iterable:\n",
|
||||
" self.add_item(item)\n",
|
||||
"\n",
|
||||
" def add_item(self, newval):\n",
|
||||
" # special case: first item\n",
|
||||
" if self.root is None:\n",
|
||||
" self.root = Node(newval)\n",
|
||||
" else:\n",
|
||||
" parent = self.root\n",
|
||||
" # traverse until we find room in the tree\n",
|
||||
" while True:\n",
|
||||
" if newval < parent.value:\n",
|
||||
" if parent.left:\n",
|
||||
" parent = parent.left\n",
|
||||
" else:\n",
|
||||
" parent.left = Node(newval)\n",
|
||||
" break\n",
|
||||
" else:\n",
|
||||
" if parent.right:\n",
|
||||
" parent = parent.right\n",
|
||||
" else:\n",
|
||||
" parent.right = Node(newval)\n",
|
||||
" break\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def print_infix(node):\n",
|
||||
" \"\"\"prints items in sorted order\"\"\"\n",
|
||||
" if node.left:\n",
|
||||
" print_infix(node.left)\n",
|
||||
" print(node.value)\n",
|
||||
" if node.right:\n",
|
||||
" print_infix(node.right)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c833bb06-4b02-4f50-bab9-ab1d30092144",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Tree traversal is inherently recursive, so we'll use a recursive function to print the tree in sorted order.\n",
|
||||
"\n",
|
||||
"Most tree algorithms will operate on the left & right subtrees the same way, so we can write a recursive function that takes a node and calls itself on the left & right subtrees."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "4f652851-2fbd-42c1-adb3-cb352657bb5a",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Bear\n",
|
||||
"Fox\n",
|
||||
"Rabbit\n",
|
||||
"Raccoon\n",
|
||||
"Wolf\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"tree = BST()\n",
|
||||
"tree.add_item(\"Fox\")\n",
|
||||
"tree.add_item(\"Wolf\")\n",
|
||||
"tree.add_item(\"Bear\")\n",
|
||||
"tree.add_item(\"Raccoon\")\n",
|
||||
"tree.add_item(\"Rabbit\")\n",
|
||||
"print_infix(tree.root)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "44e92462-532b-4340-8c9b-52314870677f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"#### Aside: defaultdict\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"# common pattern:\n",
|
||||
"if key not in dct:\n",
|
||||
" dct[key] = []\n",
|
||||
"dct[key].append(element)\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"We can instead use `collections.defaultdict`:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "a06805c2-75ae-46e3-9916-f4ee8cca6080",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"set()\n",
|
||||
"defaultdict(<class 'set'>, {'newkey': set()})\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from collections import defaultdict\n",
|
||||
"\n",
|
||||
"# give defaultdict a function that it will use to generate missing keys\n",
|
||||
"dd = defaultdict(set)\n",
|
||||
"\n",
|
||||
"print(dd[\"newkey\"])\n",
|
||||
"print(dd)\n",
|
||||
"\n",
|
||||
"dd[\"newset\"].add(1) # can add to set without ensuring it exists"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ba2d9950-e5cf-4d11-9307-f1fa37f01e67",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Graphs\n",
|
||||
"\n",
|
||||
"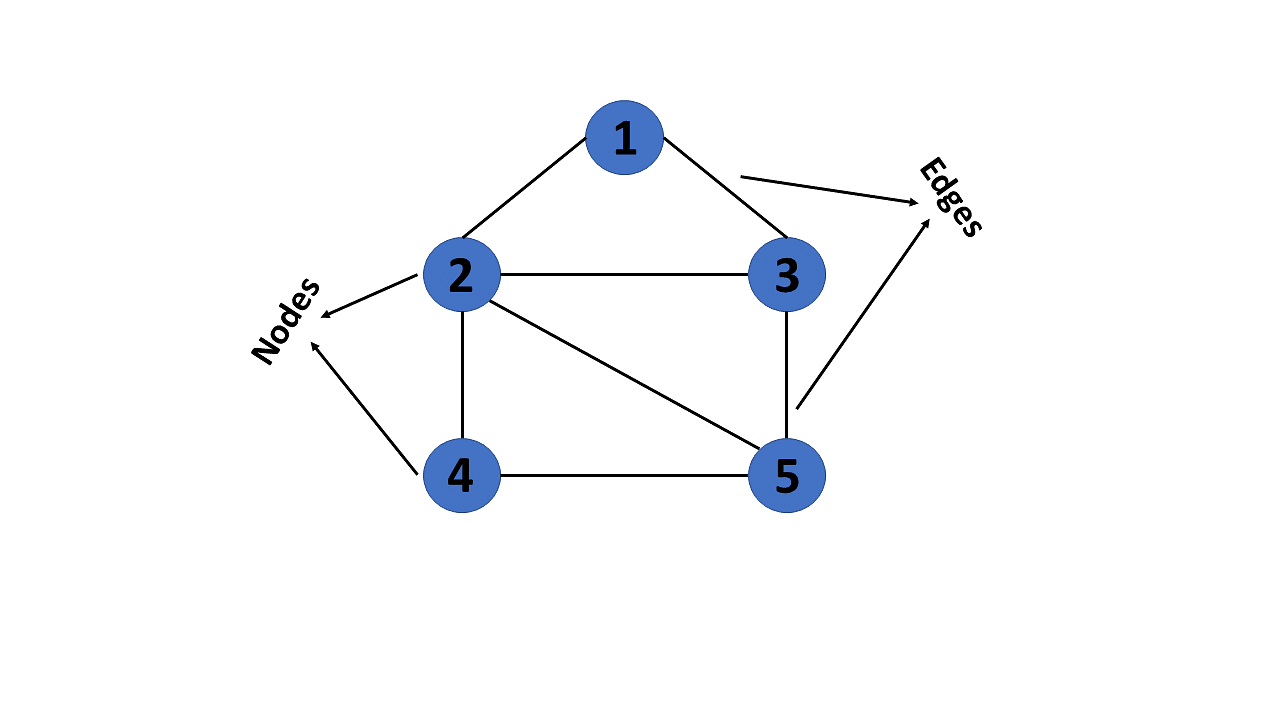"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "323a6e33-76b7-41b7-97b9-e4dfa04d6bb4",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class Graph:\n",
|
||||
" def __init__(self):\n",
|
||||
" # create a dictionary where every string maps to a set of strings\n",
|
||||
" self.edges = defaultdict(set)\n",
|
||||
"\n",
|
||||
" def add_edge(self, node1, node2):\n",
|
||||
" # add in both directions, could alter for directed graph\n",
|
||||
" self.edges[node1].add(node2)\n",
|
||||
" self.edges[node2].add(node1)\n",
|
||||
"\n",
|
||||
" def find_path(self, from_node, to_node, seen=None):\n",
|
||||
" if not seen:\n",
|
||||
" seen = set()\n",
|
||||
"\n",
|
||||
" if to_node in self.edges[from_node]:\n",
|
||||
" return (from_node, to_node)\n",
|
||||
" else:\n",
|
||||
" for sibling in self.edges[from_node] - seen:\n",
|
||||
" return (from_node,) + self.find_path(\n",
|
||||
" sibling, to_node, seen | set(sibling)\n",
|
||||
" )\n",
|
||||
" # return self.find_path("
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "867f5186-e308-4d2f-9766-713ecb352f99",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"('A', 'D', 'B')"
|
||||
]
|
||||
},
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"g = Graph()\n",
|
||||
"g.add_edge(\"A\", \"D\")\n",
|
||||
"g.add_edge(\"B\", \"D\")\n",
|
||||
"g.find_path(\"A\", \"B\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "a9acaa28-8a24-41c5-86c0-4342365533f6",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"('A', 'B', 'C', 'D', 'E')"
|
||||
]
|
||||
},
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"g = Graph()\n",
|
||||
"g.add_edge(\"A\", \"B\")\n",
|
||||
"g.add_edge(\"B\", \"C\")\n",
|
||||
"g.add_edge(\"C\", \"D\")\n",
|
||||
"g.add_edge(\"D\", \"E\")\n",
|
||||
"g.find_path(\"A\", \"E\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "615230a9-5f7c-47c9-9d5e-83d37081bc47",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Discussion\n",
|
||||
"\n",
|
||||
"* Graphs & Trees in the real world?\n",
|
||||
"* Alternate implementations?\n",
|
||||
" * NetworkX"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "45d51cd1-9d2b-40dd-95b2-f51f11b49b9e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Tries\n",
|
||||
"\n",
|
||||
"Usually pronounced \"try\" to differentiate it from trees.\n",
|
||||
"\n",
|
||||
"A **trie** is a data structure that stores data associated with string keys similar to a dictionary in many ways. (Python `dict`s are a different data structure: **hash tables**.)\n",
|
||||
"\n",
|
||||
"A **trie** is a specialized data structure, particularly useful for partial matching of strings. The way the data is stored enables efficient lookup of all strings that start with a given prefix, as well as \"fuzzy search\" where some characters don't match.\n",
|
||||
"\n",
|
||||
"Each node in a **trie** contains:\n",
|
||||
"\n",
|
||||
"- an fixed-size array of children\n",
|
||||
"- a value\n",
|
||||
"\n",
|
||||
"Let's imagine a simplified version of a **trie** that can only store string keys with the letters \"a\", \"b\", \"c\", and \"d\".\n",
|
||||
"\n",
|
||||
"So keys \"a\", \"ba\", \"dddddd\", and \"abcdabcdaabcad\" would all be valid.\n",
|
||||
"\n",
|
||||
"Now, instead of `linked_list.next` or `tree_node.left`, we will have four children, so we'll store them in a tuple:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "1ed75b91-54fe-4650-965d-ef26507788b9",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"\n",
|
||||
"class TrieNode:\n",
|
||||
" def __init__(self, value=None):\n",
|
||||
" self.value = value\n",
|
||||
" self.children = (None, None, None, None)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4ad2dec4-dc42-48bd-a144-d5c61d60dfdb",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Notice that we **do not store the key**!\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"trie = Trie()\n",
|
||||
"trie[\"a\"] = 1\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Represents a tree with a single key \"a\". The node \"X\" is the 0th child of the root node. It would have no children set, and a value of `1`.\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
" root\n",
|
||||
" / \\\\\\\n",
|
||||
" X\n",
|
||||
"//\\\\\n",
|
||||
"```\n",
|
||||
"Let's look at a trie where someone has also set `trie[\"aba\"] = 100`\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
" root\n",
|
||||
" / \\\\\\\n",
|
||||
" X \n",
|
||||
" /|\\\\\n",
|
||||
" Y\n",
|
||||
" /\\\\\\\n",
|
||||
" Z \n",
|
||||
" //\\\\\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Each node has four children, the 0th child being associated with the value \"a\", the 1st with \"b\", and so on.\n",
|
||||
"\n",
|
||||
"- X is the same as before `value=1`. It now has a child node \"Y\" in 1st position, associated with \"b\". \n",
|
||||
"- Y has no `value` set, because it only exists to build out the tree in this case. It has a child at \"a\" position (0).\n",
|
||||
"- Z is at a terminal position and would have `value=100`. Since the path from the root is \"aba\" that is the key associated with the value."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "3c397fb5-0503-4d8e-a13d-58b6d5cd6943",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Lookup Algorithm\n",
|
||||
"\n",
|
||||
"Traversing the tree is done by a simple recursive algorithm:\n",
|
||||
"\n",
|
||||
"- if there are more letters in the key: convert the next one to an index and traverse to that child node\n",
|
||||
"- if there are no more letters: the current node is the destination\n",
|
||||
"\n",
|
||||
"The correct behavior when encountering a child node that does not (yet) exist depends on the nature of the traversal:\n",
|
||||
"\n",
|
||||
"In a lookup (such as `__getitem__`) the key in question must not be in the **trie**.\n",
|
||||
"If a value was being set, the node should be created.\n",
|
||||
"\n",
|
||||
"### Note/Project Hint\n",
|
||||
"\n",
|
||||
"`value=None` will create problems in practice, because you should be able to set `trie[\"abc\"] = None` and not have it treat it as if the data was deleted.\n",
|
||||
"\n",
|
||||
"Instead, you will probably want to use different values for unset variables. It is common to make a \"sentinel\" class for this, a class that is used to create a unique value (like `None` being the sole instance of `NoneType`.).\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"class DefaultColor:\n",
|
||||
" \"\"\" Used as a sentinel class. \"\"\"\n",
|
||||
"\n",
|
||||
"def set_background(color=DefaultColor):\n",
|
||||
" \"\"\"\n",
|
||||
" This function exists to set the background color.\n",
|
||||
" (In reality, to demonstrate a time when you might treat None and an unset value differently.)\n",
|
||||
" \n",
|
||||
" If color is set to None, the background will be transparent.\n",
|
||||
" If color is not set, the background will default to the user's choice.\n",
|
||||
" \"\"\"\n",
|
||||
"```\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4aef9799-2f13-4c7c-ae62-ac8e6ed22ca3",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Trie Complexity\n",
|
||||
"\n",
|
||||
"Trie traversal complexity is `O(m)` where **m** is the length of the key strings. \n",
|
||||
"\n",
|
||||
"This in practice would likely be much lower than **n**, the number of words in the data.\n",
|
||||
"\n",
|
||||
"### Discussion\n",
|
||||
"\n",
|
||||
"- How would prefix lookup work?\n",
|
||||
"- Wildcards?"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "0939902d-b50b-4073-92ab-4df03bc1b6fb",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.15"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
Loading…
Reference in a new issue